


DeepMind, a Google-affiliated company, introduced AlphaGo a few years ago, and it is a company that attracted interest in artificial intelligence not only in Korea but also around the world.

Deep Mind then improved AlphaGo, which last year introduced AlphaGo Zero. Alpha Gao Zero no longer teaches bad guys, but AI plays against each other. Algorithms have been greatly improved, reaching the level of 100: 1 to beat the existing alpha.
Alpha Zero learns how to keep on his own and remembers it. Having the ability to repeat it on its own, it can handle tens of millions of exercises. The existing Alpha has learned a pattern of victory by letting human beings learn a great deal of data, and learned the way of thinking of human being. However, Alpha Goo Zero, who learned to play Badu in zero state without borrowing human hands, crossed the existing AI, learning Baduk without receiving the influence of human being at all.
Alpha Zero first learns basic rules about Go, then learns the rest by learning to repeat the game directly. After three days of studying, it is said that the level reached beyond the existing alpha level. After more than 21 days of learning, Alpha Gozo exceeded the Alpha Go Master, who won 60 in online competition. After 40 days, I went through all the existing Alpha versions and fully learned how to win by self-study alone. It uses reinforcement learning and allows you to learn how the neural network wins, giving you a reward for victory. Alpha Zero repeats the process of remembering how to build up know-how while playing against each other and winning here. It shows the possibility of going beyond the limits of human knowledge. It is easy to learn how to win unconventional victories.

Unlike the previous version, Alpha Zero only receives information about the stone and black stone placed on the checkerboard. The existing Alpha has used the policy network and the value network, but Alpha Zero has integrated it into one so that it can be efficiently learned and evaluated. It also uses a technique of stoning randomly to see which way is more advantageous during the match. This makes it possible to learn more efficiently than the existing Alpha and get results. Alpha-Zero has been able to drastically reduce power consumption because it can learn only a few processors and TPUs.

Deep Mind did not stop here, but later introduced AlphaZero and played board games in addition to Go. Alpha Zero was developed based on the Alpha Go. With just four hours of learning, we lightly overtaken Stockfish, the world’s strongest open-source chess engine. Alpha Zero had 28 wins and 72 draws during the 100th game. Alpha Zero also learns how to win AI without knowing how to play a human game like Alpha Zero. Alpha Zero uses reinforcement learning, so you do not need to learn the same expertise. Alpha Zero assumes the next number to be 80,000 in a second, but Stockfish reaches 70 million in a second.
Alpha Zero is able to demonstrate superhuman ability in games like chess within 24 hours without expertise. Alpha Zero won the Elmo, the strongest long-term program in the world, after only two hours of learning.

Deep Mind has developed FTW (For the Win), an AI that can transcend humans in the first person shooter FPS game. It’s not just that you can win, but you can work with human team members and enjoy multi-games.
Of course, artificial intelligence using open AI (Open AI) in 2017 has been a topic of human victory in Dota 2. This AI played a 1: 1 showdown. It was a self-learning type of technology that used the reinforcement learning method to gradually learn the game style while learning the game style without using the imitation or tree navigation. Deep Mind also said he was studying AI for StarCraft II.
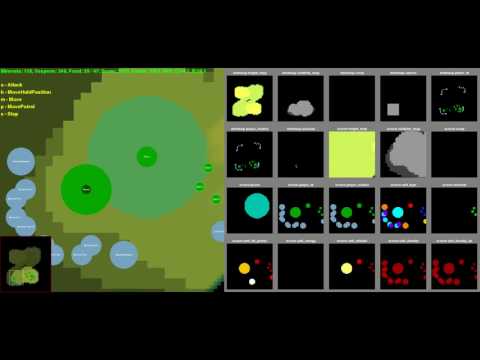
The deep-minded FTW introduced a demo using the Quake 3 Arena, a game released in 1999. Quake 3 teams up like a flag catching game and unleashes a way to take the other flag. FTW has said that it has learned to aim at teaming with humans in this process.

The capture of the flag itself is a simple way to win if you bring the flag to your side in your opponent’s camp, but the movements according to the momentary situation are complicated. The map is not used in the same place, but it changes every time you play. For this reason, GTW does not remember map layouts. Also, to grow AI like a human, you need to recognize screen pixels like humans, rather than reading the parameters directly in-game like an existing game AI.

The Deep Mind side has randomly matched 40 human gamers and 30 FTWs and trained more than 450,000 times. In this process, the neural network was formed and the motivation through the progress of the game was fed back and raised the level.

In the graph showing the growth status of the FTW, the horizontal axis indicates the number of games, and the vertical axis indicates a stronger degree of gamers. The blue line shows the level improvement of FTW. Over 150,000 times, it already exceeds the human average gamer level and reaches the highest score when it reaches about 450,000 times.

The FTW not only defends the team’s strength in flag busting, but also assists with peers (including humans), as well as suppressing opponents’ positions. It is also possible to learn to cooperate with human beings. It is through reinforcement learning that these human and artificial intelligence cooperate together. The goal of the project is to improve the reinforcement learning to a group-level education method and develop AI agents that can form a team with humans.

The goal of Deep Mind is to solve the problems humanity faces with artificial intelligence technology. By applying artificial intelligence to the medical field, it can be used to detect incurable diseases early or to control power demand. The same is true of data mining, which draws insights from vast amounts of data. In this respect, though there are many negative opinions about artificial intelligence, Deep Mind CEO Demise Hasabith emphasizes that it will have a positive impact on humanity.
Surveys of scientists to determine when artificial intelligence will transcend human levels have predicted that translators in 2024, trucking in 2027, salesmen in 2031, and surgeons in 2053 will be possible . If this development actually takes place, the human labor force may be shifted to the point of focus. The human passing of FPS game after Go game, board game, and now watching through deep mind can be seen as a teacup typhoon just right now in the game. However, it is clear that these changes are gradually coming to reality.