

A technique of eliminating or correcting an object from a still image using a deep running or the like has already been realized. However, Google is developing a technology that focuses on the depth of the video to erase a person or object from a video or synthesize objects that do not actually exist.
It is not so difficult to make 3D images of fixed camera images. However, it is very difficult to 3Dize moving images of both camera and subject. Such an image does not work effectively with existing algorithms that use triangulation principles to predict the distance from the fixed camera to the subject and to grasp the image in three dimensions.
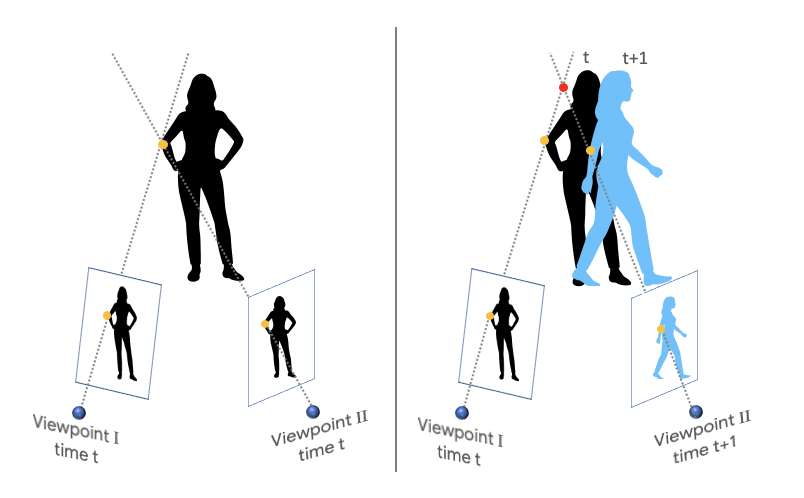
Google has noticed the explosive popularity of the Mannequin Challenge around 2016. Anyone who challenges the mannequin challenge moves at the same time as the mannequin, taking a floating posture. With this Mannequin Challenge, Google is stopping and learning AI through deep-running based on 2,000 video-only moving images.
The mannequin challenge was a camera training of moving images. Google’s goal is to capture moving images of people and cameras as 3D images. Google has introduced a mechanical learner kinematics learning machine to model two eyes of humans. We compare the frame with the image and the other frame to calculate the optical flow representing the motion of the object as a two-dimensional vector, and grasp the change in pixel unit.
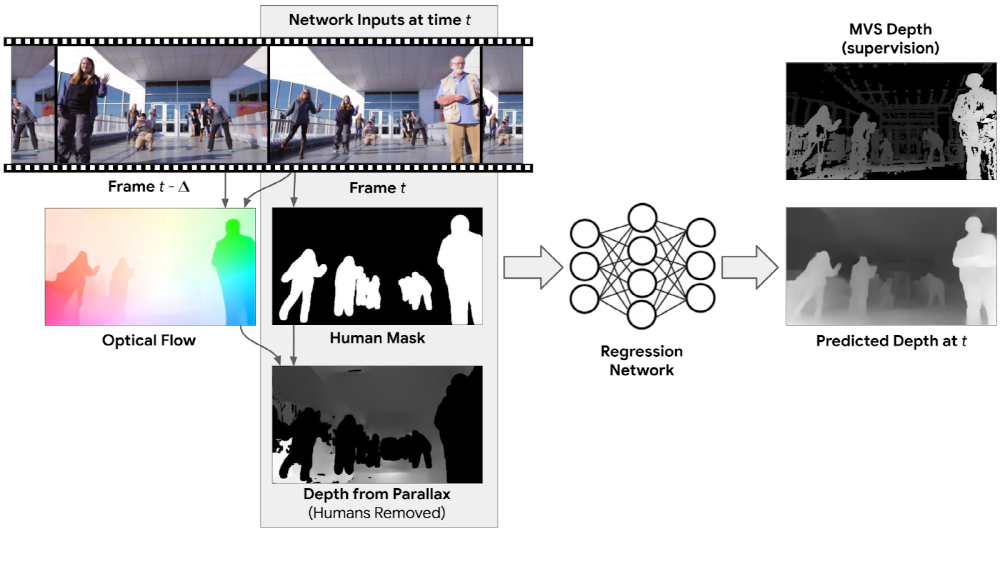
We use this method to predict the depth and create a depth map of the image. You can add various effects to the image using the depth map. For example, you can use synthetic techniques to focus on the screen and blur other objects. Of course, you can also focus on the background. Depth maps using deep runs allow you to do this in real time. In addition, you can insert objects that do not actually exist. For example, you can change the image to use 3D glasses or make people disappear from the image. For more information, please click here .












Add comment