

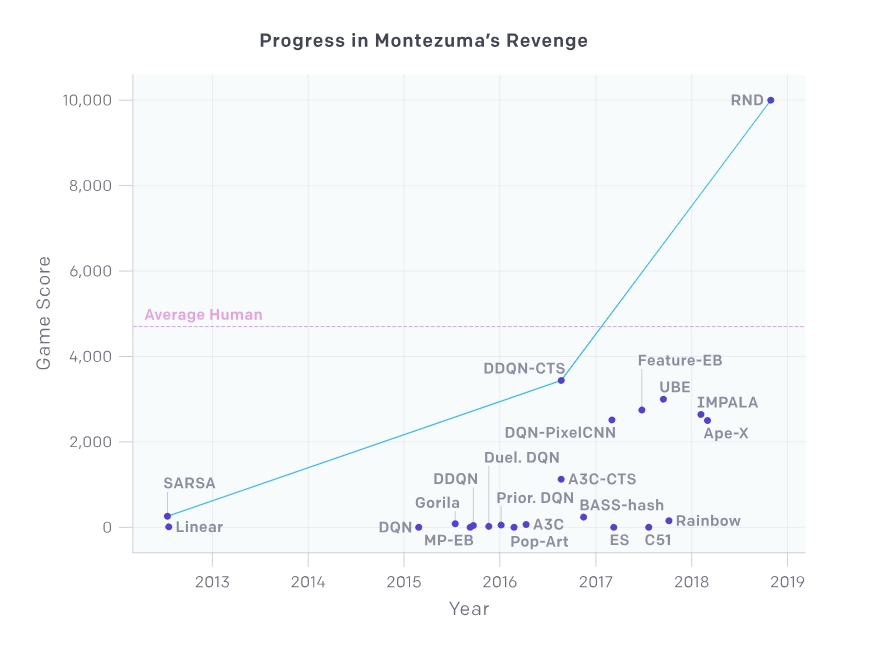
RND (Random Network Distillation) developed by AI nonprofit research institute open API (API) is a prediction based method that learns reinforcement learning agent by searching environment according to curiosity. The Open API, however, says it has succeeded in learning the agent, using scores like this in the game Montezuma’s Revenge, which outperformed the human average score.
RND recommends an agent that runs under unfamiliar conditions that can not predict how fixed arbitrary neural networks will work. Obviously, it is difficult to predict what will happen in unfamiliar situations, so the rewards are bigger.
RND can also be applied to any reinforcement learning algorithm, and its implementation is simple and efficient.

The use of the game Montessara’s revenge verified the accuracy of RND. The reason for selecting this game is that DQN, a game-learning AI developed by Google, could not exceed the human average score of 4,700. In Montesuma’s multiple level 1, there are 24 rooms available, and only 15 DQNs were available.
On the other hand, the AI agent learned by using RND was able to search all 24 rooms of level 1. It is also possible to exceed the human average score. If you play this game with various AI agents, it is said that RND is beyond the human average score.
Montesuma’s revenge is a classic game of DQN, a Google AI, that falls off the stage, touches the skull, or the protagonist dies.
DQN (Deep Q-Network) was developed by Deep Mind, an artificial intelligence company under Google. A general purpose learning algorithm based on machine learning and neuroscience. Given the simple instructions to maximize the game screen output signal and score, the rules required for the game are learned by playing the game several times directly.
DQN has mastered all 49 games of the Atala 2600 games in a matter of hours, 43 out of 49 scored higher than their AI, and 29 scored higher than professional gamers.
However, this DQN has also struggled with the revenge of Montesuma, which was introduced above. DQN went through a hundred million exercises in Room 1 and 2 and found a way to break the room in different patterns with different motions. As a result, it will stay in the search for 15 out of 24.
For this reason, the results of testing various games with DQN showed that there are games that can do better than humans, but there are things that are not. DQN uses reinforcement learning, a type of learning that achieves its objectives through trial and error, while repeating gameplay several times, as mentioned above. Self-learning and accumulation of knowledge through this.
In Atari 2600 games, when it was targeted to 50 people, 29 people exceeded humanity, but Montessuma’s revenge was 0%.
For this reason, DeepMind has improved the DQN algorithm, stabilized learning, prioritized previous game experiences, and standardized output, collected and re-measured.
In July, the Open AI announced that it had scored more than 70,000 points on Montesuma’s revenge. Open AI uses the Proximal Policy Optimization (PPO), a reinforcement learning algorithm that supports OpenAI Five, a human team winner in a 5: 5 battle, such as Dota2, . This is to optimize the game score.
At that time, the open AI had to solve two learning problems that would require the AI agent to search for a series of actions leading to positive rewards, a series of behaviors to remember, and a slightly different situation to get high scores in the game “He said.
When working randomly and rewarding, the AI agent can remember that this action is rewarded and can perform the action in real situations. However, if you have a more complex game, the series of actions will take longer to get rewarded, so the probability of this series of random work is lower. In other words, reinforcement learning may not be suitable for learning in complex games where a series of long tasks may lead to rewards. In contrast, a short action can work well in a simple game that will result in rewards.

At the time, the open API took a way to learn how AI agents play in the nearest part of the demonstration play data at the time of reinforcement learning. This is repeated and the agent continues to learn to play the game and score higher than the human player.
However, step-by-step learning methods are much easier than learning games from the beginning, but there are a lot of problems. Because of the randomness of the task, certain action sequences may not be reproduced accurately. In this respect, we need to be able to generalize this unequal state. For example, according to the announcement of the open time AI may well succeed In a plurality of Montezuma In other games will apply dwaetdaneun not good (one open-source AI development time is github is disclosed in).
There is also a need for a balance between exploration and learning. If the AI agent’s behavior is too random, you can make mistakes. Conversely, if the AI agent’s behavior is too determined, he or she will stop learning while exploring. In this respect, we must find an optimal balance between exploration and learning. As reinforcement learning evolves, we can expect algorithms that can respond to random noises or parameter-dependent choices.
In this regard, the AI agent enhanced with RND showed various possibilities. The AI agent moves left or right to gain the key and advance the stage. Do not fall off high, leave the footsteps, move with a rope or step, not just collect the keys, but collect the jewels to increase your score. When you touch it, the gate gap that is dying goes out deliberately. It can break many levels like this.
It does not just break the game, it also dances with the skeleton that appears on the stage. Learning with RND makes it possible for AI to create agents with playfulness that they did not even think about.
When DQN and other artificial intelligence can perform such a variety of tasks, it can be expected to extend its scope to applications that are beneficial to society, such as outside the game and health care.












Add comment