
SpecAugment is a technology that allows Google to automatically recognize speech without using a language model.
Google is working on automatic speech recognition technology that automatically recognizes and converts speech into text, such as Cloud Speech-to-Text. As noted earlier, the specification parameter raises the model’s ability to automatically recognize speech without using a language model.
Language models are mathematical representations of word and word relationships in language. It is possible to convert a voice that is just a sound into a meaningful sentence by learning what word comes after the word. Therefore, AI that enables automatic speech recognition should be trained according to the language model.
The spec components released by the Google research team allow you to build automatic speech recognition models that are more accurate than traditional methods without the help of a language model. The existing automatic speech recognition model converts the voice data into a visual representation in spectral form and inputs it into the network model. Recognition processing is performed in the spectrum, but the provided data themselves require large amounts of voice data and require extensive computational costs.
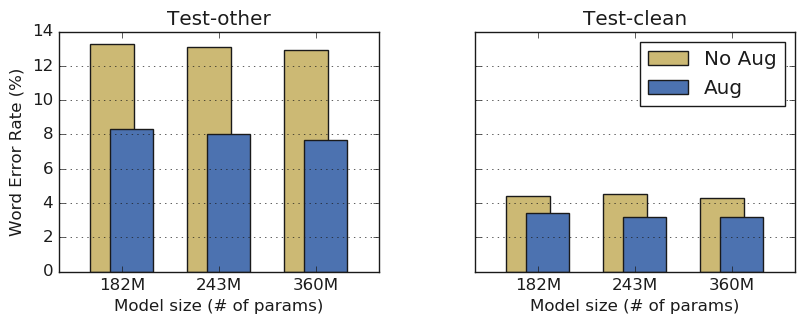
The spectral data is directly edited and the spectral data is masked to enhance the spectral data. This prevents over-learning of the model and enables speech recognition to be performed with higher precision than existing models without language model support. The recognition accuracy of the conventional automatic speech recognition model is 12 ~ 14% if the noise signal is negative, and 4 ~ 5% if the noise signal is low. The automatic speech recognition model using the specification parameter is about 8% in the case of loud voice and 3% in the case of a small voice signal.
If you have an automatic speech recognition model supported by this technology, you can use it in e-mail dictation mode, or you can expect to use such as converting interactive AI voice on smart speaker to text. If the recognition rate is low, it may become possible to enter the voice promptly rather than typing with the actual finger. For more information, please click here .












Add comment