

The voice of the speaker alone can identify information such as sex, age, and even where you are from. Speech2Face is an AI that generates images in anticipation of human speech and speech. It is being developed to derive human physical characteristics from speech.
Speech to Face is a video uploaded on YouTube that teaches the machine about age, gender, race, voice and sound of the speaker and generates the image of the person’s face in the voice. The video used in the study reaches millions of times, and Speech to Face has learned more than 100,000 people’s voices and faces.
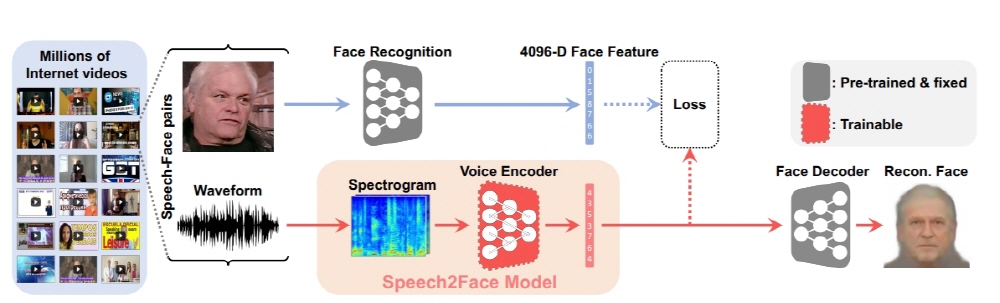
Speech-to-face actually compares the face image generated by the voice with the actual face, but the race, gender and age are similar, although the details are different. In addition, the face-to-face images produced by the face are all expressionless.
According to the study, face-to-face images are mostly age, race, and gender, and the longer the voice is input, the more accurate it is, but it is not perfect. Even if the same person creates a face image from a Chinese speaking voice and an English speaking voice, respectively, a white image is produced by the English language and an Asian image is generated by the Chinese language. Also, in the case of bass, men tend to produce images of women, and highs of tones. For more information, please click here .












Add comment