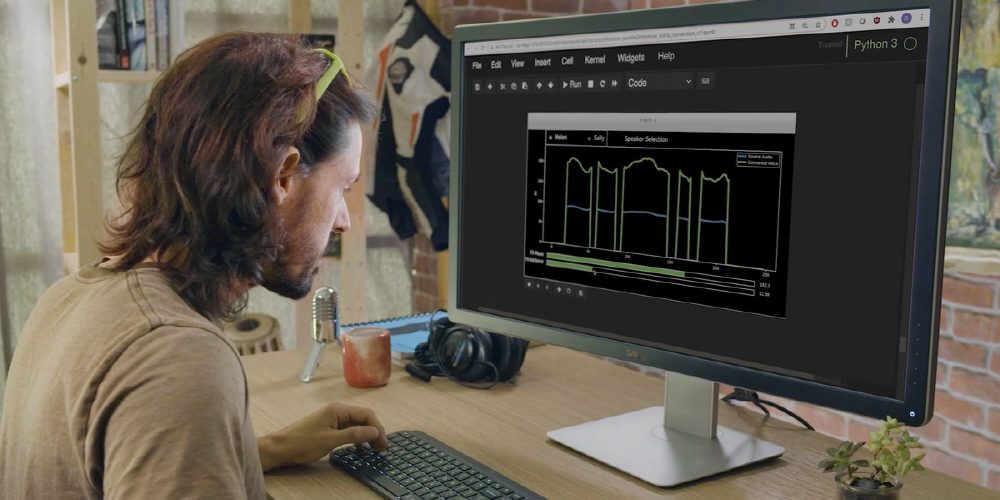
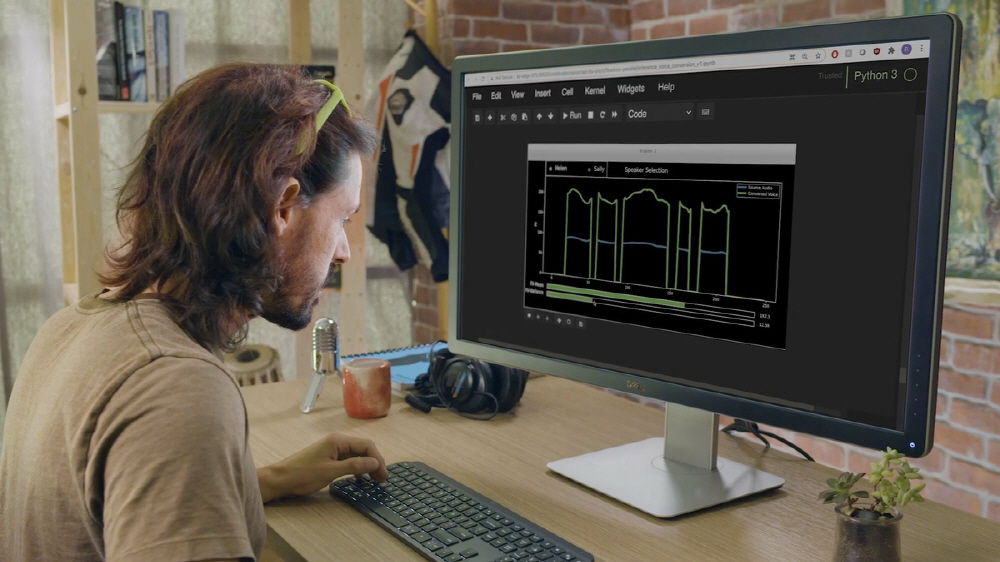
Nvidia announced that it is developing an AI that can voice human-like expressions during INTERSPEECH 2021, a speech technology conference.
Synthetic voice automatic guidance services and old navigation guidance were mechanical. On the other hand, the voice assistant mounted on a smartphone or smart speaker has evolved considerably. However, there is still a big difference between a real human conversational voice and a synthetic voice. It is easy to distinguish whether it is a real human voice or an AI synthesized voice. According to Nvidia, it’s difficult for AI to perfectly mimic the complex rhythms and intonations of a human voice.
In the video Nvidia introduces new products and technologies, humans have been the narrator so far. This is because, until now, there was a limit to the voice tempo and pitch control that can be synthesized using the voice synthesis model, so it was impossible to speak like a human narrator to stimulate viewers’ emotions.
However, the NVIDIA speech synthesis research team developed RAD-TTS, a text-to-speech synthesis technology, and greatly improved NVIDIA speech synthesis technology. NVIDIA NeMo is an open-source interactive AI toolkit that NVIDIA is developing for the study of automatic speech recognition and natural language processing text-to-speech synthesis. The human voice can be viewed as an instrument and the synthesized voice pitch, duration, and intensity can be precisely controlled on a frame-by-frame basis.
In general, machine voices have a unique intonation, so there is a sense of incongruity. However, the voice converted to Nvidia Square plays smoothly without any discomfort. In addition, the AI side can adjust the synthesized voice to emphasize specific words or change the narration speed to match the video.
In addition to voice synthesis narration, he can also be active in the music production scene. For example, when making music, you have to record multiple voices in the chorus part and overlap them. However, it is also possible to record chorus parts without gathering a majority using synthetic voices.
The AI models included in Nvidia Nemo work with Tensor Cores, Nvidia’s GPUs, by learning tens of thousands of hours of speech data from Nvidia’s DGX system. Nvidia Nemo will also show models trained on Mozilla Common Voice, a dataset containing 14,000 hours of speech data in 76 languages. Nvidia says it aims to democratize voice technology using the world’s largest open source voice dataset. Nvidia Nemo has an open source on Github. Related information can be found here.












Add comment