

DeepMind, an artificial intelligence company, has announced an AI that allows you to learn how to win, such as Go, Shogi, and Chess, with zero rule knowledge. The AI, named MuZero, is a big step towards self-thinking AI.
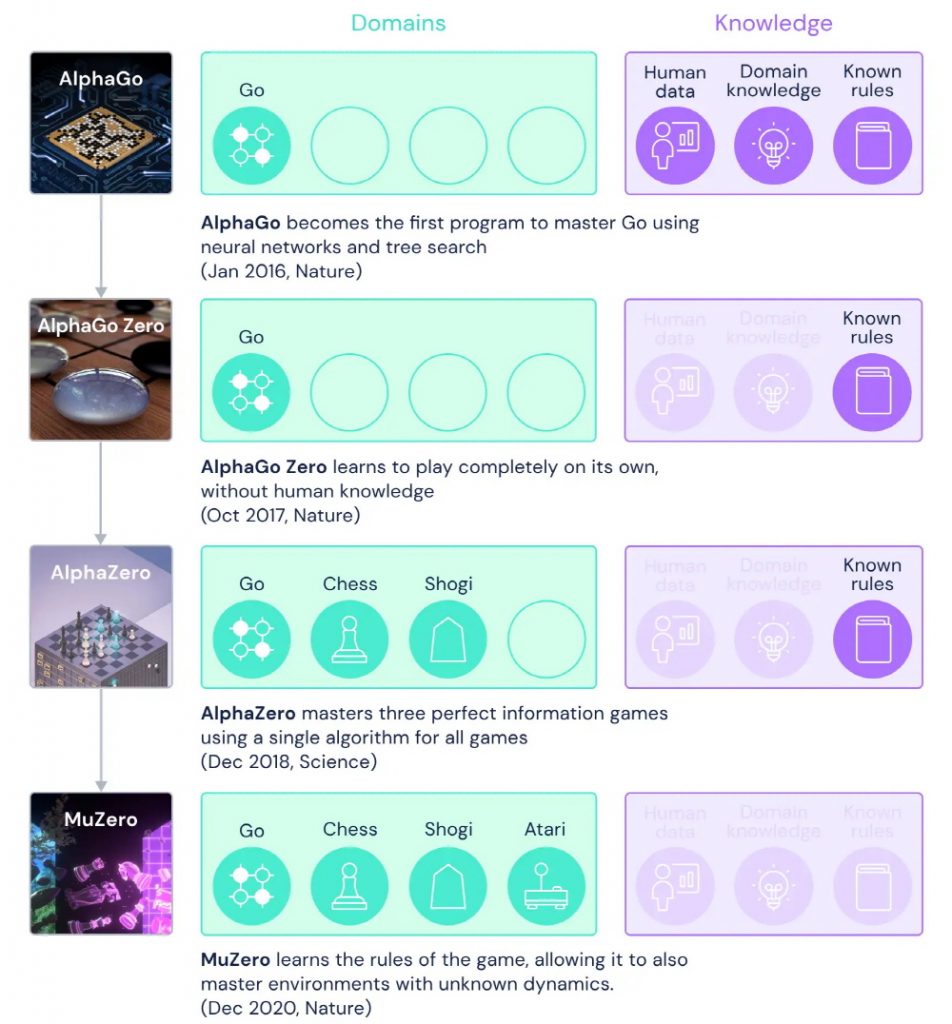
AlphaGo, an artificial intelligence developed by DeepMind, made its name known by winning over 9 Dan Lee, the world’s best knight. It has been pointed out that it is not suitable for solving problems in reality where rules are not clear, because Alpha Go has overwhelming power in Go, but it cannot solve problems with high uncertainty.
DeepMind’s newly announced MuZero is a new approach to solving AlphaGo’s challenges. If you look at the difference between Alpha Go and Alpha Go Zero, Alpha Zero, and Mu Zero, Alpha Go only plays Go and needs to learn human data, Go knowledge, Go rules, etc. in advance. In contrast, MuZero can derive an optimal solution through self-learning without prior learning about Go, chess, shogi, and Atari.
It is explained that the use of Atari in the development of MuZero is to provide simple progress indicators such as game scores and rich tasks for players to formulate sophisticated strategies. MuZero’s goal is to train AI to resemble human thinking about problems as well as educate them to solve specific problems.
Specifically, Muzero models three elements without using a trained model. The value of how good the current position is, the policy that determines which action is best, and the payoff that determines how good the last action is.
MuZero learns and understands in a neural network using three factors what will happen when taking or planning a specific action. DeepMind’s side explained that MuZero developed artificial intelligence that plays Atari before MuZero, but MuZero has higher performance and is comparable to AlphaZero’s performance in Go, Chess, and Shogi.
The research team expects the results of this study to be an important step toward developing AI with better problem-solving capabilities. Related information can be found here .












Add comment