

DeepMind, an artificial intelligence company under Google, has developed popart (PopArt), a technology that can compensate for the rewards of multitasking learning through artificial intelligence.
Deep mind has developed artificial intelligence AlphaGo, which has brought the artificial intelligence craze to the 9th stage in Korea, and also developed DQN, which is artificial intelligence that learns games better than humans by learning reinforcement learning .
This is why Deep Mind developed Pop Art this time. Multitasking learning is needed to allow one agent to learn how to solve multiple tasks. Multitasking learning is one of the long-standing goals in artificial intelligence research. Agents such as the DQN mentioned above also use algorithms that can learn by themselves and learn multitasking while playing multiple games. As the artificial intelligence research becomes more complex, it is currently mainstream to install various professional agents in related research.
In this situation, the algorithm that learns multiple agents should be able to construct multiple tasks through a single agent. Multitasking learning algorithms become important. However, there is a problem with this multitasking learning algorithm. The reinforcement learning agent uses different compensation factors to determine success.
Let’s take an example. If the game pong is learned in the DQN, the agent receives one of -1, 0, +1 for each learning phase. But if you learn Pac-Man, you can get hundreds or more rewards for each learning phase. With the same compensation scale, you can not measure which tasks are more important.
Even if the individual compensation amounts are the same, the compensation frequency may be different. Agents tend to focus on larger rewards, so different compensation scales and frequencies can lead to higher performance on certain tasks and lower performance on other tasks.
To solve this problem, regardless of the amount of compensation that can be gained per game, you must standardize the amount of game-specific compensation so that the agent can judge the game as the same learning value. That is pop art.
According to Deepmind, applying Pop Art to the latest reinforcement learning agent has resulted in creating a single agent that can learn more than 57 different games at once.
Deep running updates the neural network weights so that the output approaches the target value. The same is true when using neural networks in deep reinforcement learning. Therefore, pop art standardizes the score by estimating the average value and the penetration rate of the target game score, and enables stable learning according to the change.
So far, reinforcement learning algorithms have attempted to overcome the problem of compensating scaling by using compensating clipping. The bigger score is +1, the smaller score is -1, and so on. With compensated clipping, it is possible that the agent learning is simplified, but the agent does not perform a specific operation. Multitasking learning with traditional compensation clipping is not the best option.
Again, for example, Pacman’s game goal is to score as high as possible. There are two ways to get points from Pac-Man. One is eating on stage, the other is eating items and eating monsters. Just eat regular items 10 points, eat monsters 200-1,600 points.
In this case, when using compensation clipping, it is not possible to find the difference between the point obtained by a normal item and the point when a monster is eaten. You do not want to eat monsters to get higher points.
Applying pop art instead of compensating clipping can recognize that it is important to eat monsters because compensation is standardized.
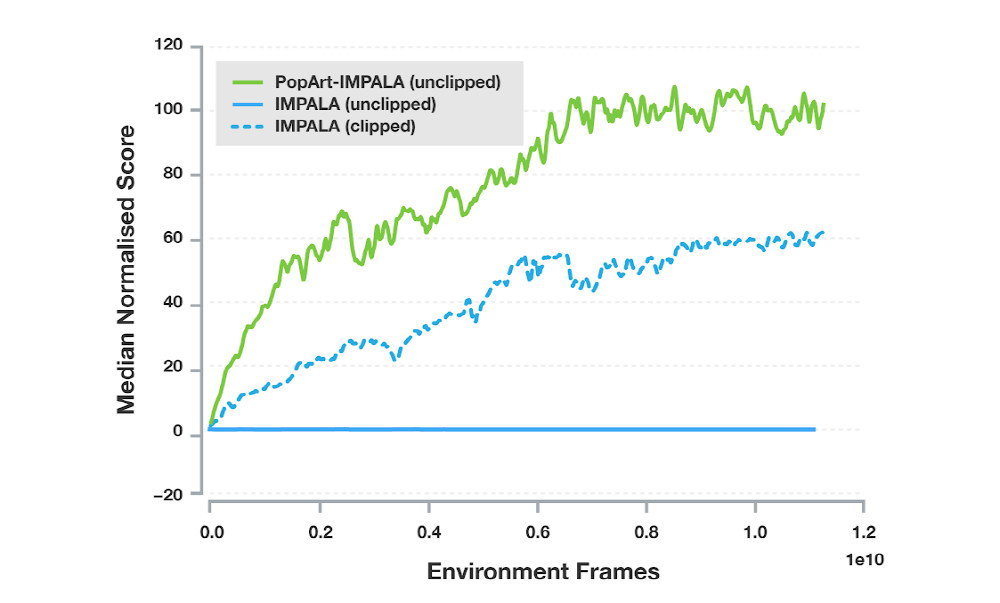
As a result of applying pop art to IMPALA, which is one of the most popular agents used by Deep Minds, the agent performance has been greatly improved. Deep Mind says it is the first time in a multitasking environment that it has achieved high performance with a single agent, and that Popart will exert a great deal of effort when learning agents for various purposes using various rewards.
The appearance of pop art is expected to be of great help in research on artificial intelligence which becomes increasingly complicated. The learning through the agent goes through the process of rewarding the agent as if giving the animal a good circus when learning the circus. In this regard, standardized rewards such as pop art seem to be of considerable help. For more information, please click here .












Add comment